Validation of the NERD Services
The platforms involved in the project have completed the integration of entity-fishing (NERD – Named Entities Recognition and Disambiguation) services. Several applications have been successfully tested on the platforms and over the coming months they will be further developed. Below are a few brief notes on the work done. To find out more participate in the webinar ENHANCING PUBLISHING PLATFORMS: ENTITIES EXTRACTION FOR OPEN ACCESS MONOGRAPHS, Monday, 05.03.2018, 14:00 – 15:00 (CET) (Click here to register).
OpenEdition
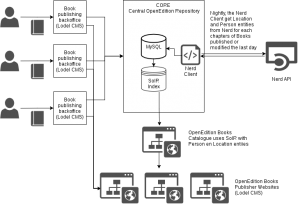
OpenEdition has integrated Entity-fishing (NERD) system into Core (the central application for managing their publications). The data extracted from their monographs (few dozens documents) were stored in a database and indexed in Solr. The process can be described in 5 steps:
- the documents are processed, using their HTML representation to segment paragraphs and sentences;
- entities classified with Named Entity Class as PERSON and LOCATION with frequency above two, are then collected in a special storage;
- all other entities are further processed using NERD_KID service in order to predict their Named Entity Class on the base their Wikidata disambiguated entry;
- all entities from each books are then aggregated together, only ones of type LOCATION and PERSON are indexed.
Göttingen University Press
Göttingen State and University Library has integrated Entity-fishing (NERD) service into the publishing workflow of Göttingen University Press (GUP) in order to enable the semi-automatic indexing of its monographs.
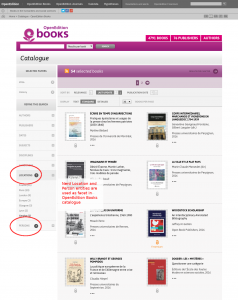
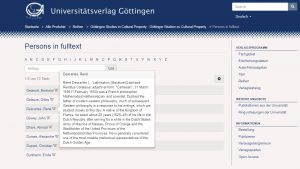
Titles, abstract and metadata of the monographs published in GUP are processed by entity-fishing (NERD) and entities classified into the Named Entities Types of PERSON, LOCATION and PERIOD are collected and shown on the GUP homepage of the book, allowing the users to quickly find the monographs in which these entities appear.
Entity-fishing (NERD) service has been integrated in the workflow used to add new books in the library, in particular when processing the metadata of the monographs, the GUP editors have at their disposal now an on-the-fly call to Entity-fishing (NERD) that autocomplete the form.
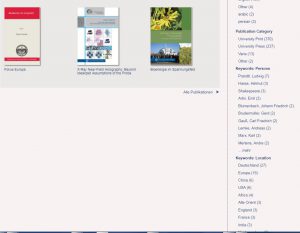
On the book or collection page, the entities are then displayed in word clouds, so that the users can immediately recognize which topics are most frequently addressed in this collection. By clicking on the different facets the user comes directly to the titles where each entity occurs.
EKT / National Documentation Center
EKT / National Documentation Center is using Open Monograph Press | Public Knowledge Project software as its e-Publishing infrastructure. Open Monograph Press (OMP) is an open source software platform for managing the editorial workflow required to see monographs, edited volumes and, scholarly editions through internal and external review, editing, cataloguing, production, and publication.
EKT has improved OMP with Entity-fishing support by integrating the service API to the OMP monographs’ landing page in order to annotate the abstract with the NERD entities:
- Colorize abstract of the monograph based on the recognized entities and their types and provide extra information of each entity from Knowledge Base,
- Index all recognized entities and a facet browsing support or even a tag cloud browsing for simplify search and discovery of OMP content.

Ubiquity Press
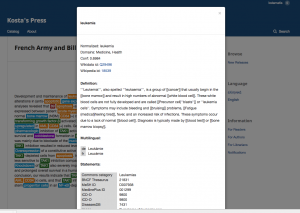
Ubiquity Press has developed an internal service (called Archiver) which receives notifications from the existing company platform when a new article has been published (using a pub-sub architecture), and POSTs its content (after formatting it as a JSON as per NERD service specifications) to the entity-fishing (NERD) API in order to retrieve all the entities and store them locally.
This internal service exposes an API to the existing UP journal frontend, where the entities are shown to the reader as clickable links referring to the Wikipedia entry for the entity; the links live in a contextual section for each article, and are easily accessible while reading the content.
OAPEN
The Entity-fishing (NERD) API will be integrated in the workflow when processing new publications entered by OAPEN. The integration will be used also on already existing English and German titles in the OAPEN Library. The result will be a publicly available data source containing all named entities from over 2000 titles.