|
|


HIRMEOS WORKSHOPS ON ANNOTATION AND METRICS FOR OPEN ACCESS MONOGRAPHS
The HIRMEOS project organizes two workshops on 10th and 11th January 2019 at INRIA in Paris:
- Why does Open Annotation matter? (10th Jan, 10:30-17:30)
- Metrics and Altmetrics for Open Access Monographs (11th Jan, 9:30-16:30)
The topics covered by these two events – annotation of scholarly works on the one hand and the collection of usage and impact metrics for Open Access digital monographs on the other – are closely linked. Remarks and comments, when made public, can be considered an indicator of resonance, influence and impact. Therefore, any service aimed at a bibliometric analysis of scholarly production must also pay attention to text annotations. To this aim, the HIRMEOS project is both implementing an online annotation tool and standardizing usage metrics and alternative metrics on its platforms.
Annotation tools help to expand scholarly content, make peer review more efficient and transparent, and promote community participation. We will focus during the first workshop – Why does Open Annotation matter? – on possible applications of the annotation service in scholarly research and teaching, scientific blogging and open peer review. We will start by considering some cultural-historical aspects of annotating texts. Afterwards, the hypothes.is tool for annotation of digital documents will be presented and it will be shown how it has been implemented and used on the digital platforms involved in the HIRMEOS project (OpenEdition Books, OAPEN Library, EKT ePublishing, Göttingen University Press, Ubiquity Press). We will then discuss specific usage scenarios and allow participants to get some practical experiences with the annotation of digital texts. To this aim, the participants will work in groups (please bring your own laptop!) and annotate different texts together. Afterwards we will discuss the experiences and try to formulate some general recommendations for the use of the annotation tool on digital monographs and other forms of texts.
The second workshop on 11th January – Metrics and Altmetrics for Open Access Monographs – will focus on the HIRMEOS service aimed at collecting and visualizing metrics and altmetric data for Open Access monographs in the humanities and social sciences. The first part of this workshop will be dedicated to presenting the implementation on the digital platforms involved in the HIRMEOS project and the technical challenges that were involved. Afterwards, together with scholars in the social sciences and humanities, digital platform providers, members of funding institutions and librarians, we will consider the reliability of the HIRMEOS metrics service and of other tools to measure resonance, influence and impact of scholarly publications. In this way, we want to critically discuss in which way metrics tools can contribute to an informed decision-making in research evaluation, publishing, and library management. The workshop will conclude by formulating some recommendations for the implementation of the metrics service on other digital platforms outside of the project.
Workshops Agenda & Presentations
Why does Open Annotation matter?
(10th Jan, 10:30-17:30)
From 10:30 Registration
11:00 – 11:15 Welcome & introduction
11:15 – 11:30 The HIRMEOS project (Andrea Bertino, Göttingen State and University Library ; Elisabeth Heinemann, Max Weber Foundation)
11:30 – 12:00 The tradition of annotation (Christian Jacob, École des Hautes Études en Sciences Sociales )
12:00 – 12:30 The Hypothes.is tool for open annotation (Heather Staines, Hypothes.is)
12:30 – 13:30 Lunch
13:30 – 14:00 The implementation of the HIRMEOS Annotation Service (Rowan Hatherley , Ubiquity Press)
14:00 – 15:00 Annotation usage scenarios
- 14:00 – 14:20 Annotation & Teaching (Micah Vandergrift, NCSU Library)
- 14:20 – 14:40 Annotation & Scientific Blogging (Mareike König, German Historical Institute Paris)
- 14:40 – 15:00 Annotation & Open Peer Review (Edit Gorogh, Göttingen State and University Library)
15:00 – 15:30 Coffee break
15:30 – 16:30 Working Groups on the annotation usage scenarios
16:30 – 17:30 Panel discussion: Feedback from the working groups and closing remarks (Chair: Pierre Mounier, Open Edition)
Metrics and Altmetrics for Open Access Monographs
(11th Jan, 9:30-16:30)
From 9:00 Registration
9:30 – 9:45 Introduction: Annotations in the HIRMEOS Metrics Service (Rowan Hatherley and Tom Mowlam, Ubiquity Press)
9:45 – 10:15 The HIRMEOS Metrics Service (Javier Arias, Open Book Publishers)
10:15 – 10:45 Coffee break
10:45 – 12:25 Metrics and national evaluation cultures
- 10:45 – 11:10 Didier Torny (French National Centre for Scientific Research)
- 11:10 – 11:35 Ioana Galleron (Université Sorbonne Nouvelle)
- 11:35 – 12:00 Gernot Deinzer (University Library of Regensburg)
- 12:00 – 12:25 Elena Giglia (Università degli Studi di Torino)
12:25 – 13:30 Lunch
13:30 – 15:10 The impact of metrics on scholarly publishers, research organisations and libraries
- 13:30 – 13:55 Rupert Gatti (Open Book Publishers)
- 13:55 – 14:20 Tom Mowlam (Ubiquity Press)
- 14:20 – 14.45 Tina Rudersdorf (Max Weber Foundation)
- 14:45 – 15:10 Charles Watkinson (University of Michigan Library)
15:10 – 15:30 Coffee break
15:30 – 16:30 Roundtable and closing remarks: metrics and the scholarly monograph (Chair: Laurent Romary, INRIA)
]]>Entity-fishing for Scholarly Publishing: Challenges and Recommendations
Andrea Bertino, Luca Foppiano and Javier Arias, Aysa Ekanger, Klaus Thoden
On 4th September 2018 the Göttingen State and University Library, with the support of the Max Weber Stiftung, organised the second HIRMEOS Workshop on Entity-Fishing for Digital Humanities and Scholarly Publishing.
Entity-fishing, a service developed by Inria with the support of DARIAH-EU and hosted at HUMA-NUM, enables identification and resolution of entities: named entities like person-name, location, organizations, as well as specialist and less commonly classified ones, such as concepts, artifacts, etc. The technical specifications of the service are described in the paper “entity-fishing: a service in the DARIAH infrastructure“, while for a quick overview of how it has been implemented on the digital platforms involved in the HIRMEOS project you can have a look at this factsheet and at the recording of the webinar organized by the SUB Göttingen.
The workshop aimed to discuss and clarify practical concerns arising when using the service and possible new use cases presented by Edition Open Access, ScholarLed and Septentrio Academic Publishing.
This report describes challenges related to the development of these applications and provides recommendations for its integration and use on digital publishing platforms. The solutions proposed can be further applied on other domains.
Beyond the tradigital format: the need for TEI XML
The new consortium ScholarLed is developing a common catalogue of all monographs published by several scholarly presses, with a recommendation system that will suggest similar books to those browsed by the user. While the initial proposal expected the similarity linkage to be done manually, ScholarLed intends to explore if entity-fishing could automate the process, finding common entities within the catalogued books. Furthermore, ScholarLed is exploring other possible use cases within the context of improving the discoverability of their publications.
Indeed, there is great potential in adopting wikidata entities as a standard metadata export. What still needs to be clarified – observes Javier Arias from Open Book Publishers – is how this data is to be disseminated and promoted to distribution platforms and data miners. In order to increase the interest in this service, the presses involved in ScholarLed think that it is essential to find the best way to export the annotations and associated Wikidata IDs along with other book metadata, avoiding these data getting lost during book redistribution or reprocessing. To this end, it would be important to embed the found wikidata entities in their TEI XML files – a feature that at present is not yet available via entity-fishing service.

With regard to the realisation of a shared catalogue for ScholarLed, Javier Arias pointed out in his presentation some specific challenges concerning its implementation in the platforms, the accuracy of the service and the dissemination of entities and metadata.
In a similar way, Klaus Thoden, who has tested how to enrich the content and extend the usability and interoperability of the books published by Edition Open Access, argues that it would be extremely important to add some kind of support for TEI XML files, allowing the user to input an unannotated XML file and get back the file with the entities embedded as TEI annotations. In the case of Edition Open Access a PDF file is just one output format amongst others and only supporting TEI XML would make the publications annotated through entity-fishing fully reusable.

Four usage scenarios for Edition Open Access in Klaus Thoden’s presentation: cross-publication discoverability of entities; interconnection of publications; links to taxonomies; search and browse functionality for entities
There are therefore some inherent difficulties with the service in relation to the use of the PDF format, which, although allowing the user an experience of the digital document as similar as possible to that of a traditional printed document, seems to somewhat limit the reuse of the annotated publications. See Luca Foppiano’s technical assessment of how to process input in TEI XML format.
Luca Foppiano notes that it could be interesting to allow the manual annotations of PDFs, however the resulting feature might not perform as well as expected and implementing might not be worth the effort.
The problem rests in how the data is segmented internally. By referring to the GROBID library, the PDF is divided into a list of LayoutTokens: every single word corresponds to roughly one token but this can vary depending on how the PDF has been generated. A LayoutToken also contains coordinates, fonts and other useful information. It is important to understand that the process is not always working perfectly. The order of the tokens might not be corresponding to the real order, and there are other small problems.
As of today, entity-fishing is the only tool available that maps entities from the coordinates extracted from the PDF. However, the opposite direction is more challenging as the coordinates associated with an entity might correspond to one or more layout token, thus matching them might give imprecise results.
A solution to this challenge could be the development of a new graphical user interface to load a PDF and give the user the possibility to manually annotate it. The output annotations will be then compatible with the LayoutToken detected coordinates.
How much editorial work is required to validate the outputs of entity-fishing?
Scholarly publishers willing to adopt entity-fishing in order to allow deeper interaction with their content are interested to maintain a balance between the benefits of such implementations and the amount of editorial work associated with them. It is necessary to develop a workflow that allows a smooth curation of the data obtained from the system, but it is difficult to assess how much time is required for the curation of the extracted entities without the editors having the system tested. Therefore, the first step in implementing entity-fishing must be to clarify carefully the specific kind of service the publisher is looking for, rather than discovering possible applications on the go. Klaus Thoden notes that since entity-fishing is a machine driven approach and can lead to results that are clearly wrong or wrongly disambiguated, the user must also be made aware of how the results came about, as the credibility of a source suffers from wrong results. If, however, it is made clear that the displayed enrichments result from automatic marking, the user records the information with a pinch of salt.
How to store data for the extracted entities and present full-annotated text?
By using entity-fishing to enrich the content of digital publications, we need to store the data for the extracted terms. At least two solutions are possible. A first possible scenario is that the editor modify the contents of the paragraph fields in the database and add additional span elements. Otherwise, the data can be stored elsewhere by using standoff annotation per paragraph.
In addition, the viewer used to present the processed document should be adapted appropriately. For example, to separate the authored content and the automatic tagging, the publication viewer should contain a button where automated enrichments can be toggled. Thus, the user still has a choice of seeing or ignoring these enrichments. Furthermore, a functionality could be implemented that allows correction or flagging of incorrect terms.
Can entity-fishing be used to disambiguate digitized old documents?
Aysa Ekanger was exploring the possibility of using entity-fishing in order to recognize old toponyms and person names, and automatically disambiguate them – in a series of digitized books, Aurorae Borealis Studia Classica, and possibly in some historical maps that are now being digitized at the University Library of Tromsø. Old maps present an interest both to scholars and to the general public. For digitized maps, two hypothetical use cases were discussed: annotations and using entity-fishing to produce interactive map-viewing, with an old map and a modern equivalent side-by-side.
Another instance of map production can come from Septentrio Reports, where a lot of archaeological excavation reports from Tromsø Museum are about to be published (this is born-digital text). Apart from toponym entries in annotated PDFs, the entity-fishing tool could be used to produce a map of excavations. The map could be visualized through an appropriate tool and placed on the level of an issue, as one issue should contain 6–7 reports from different excavation sites.
Old digitized texts present some specific challenges. For instance, there is a custom of referring to scholars by latinized names: Johann Christoph Sturm is referred to as “Sturmius” in this German text from 1728. Old toponyms that would be disambiguated would be of at least two types: names of places that no longer exist and archaic names of existing places (including old orthography). In order to achieve this kind of disambiguation there are two requirements: 1) the terms are contained in a knowledge base, and 2) there is a a piece of code which can recognise the relevant tokens in the text.

Aysa Ekanger’s presentation with three possible usage scenarios: PDF annotation, word clouds and digitized maps
A further relevant technical concern, however not directly connected to entity-fishing service, is the inaccuracy of the OCR: in digitized historic texts 1–8% of OCR results are wrong. Of course, the improvement of OCR is necessary, but in the meantime the editors of the text in question may have to resort to “manual” labour for a small percentage of the text: any text mining application would therefore require a preliminary (manual or semi-automatic) correction of the errors in PDF due to the OCR process.
Best practices on how to use entity-fishing in scholarly publishing
During the discussion, it became evident how important it is to have an exact preliminary definition of the usage scenario that a content provider such as a publisher intends to develop on the basis of entity-fishing. In particular, it is important to ascertain how much work is required to manage the specific publishing service based on entity-fishing.
From a more technical point of view, these are the key recommendations made by the developers of entity-fishing:
- Consider the web interface as a prototype and not as a production-ready application
The demo interface shows “what can be done”. There is a step in the middle that is to adapt the service to your own requirements and this has to be done by a data scientist, someone that can quickly look up the data and get some information out of it. For example, the language R can be used to read, visualise and manipulate a list of JSON objects. In addition, you should avoid to evaluate the service on the basis of restricted manual tests. Proper assessment must be carried out with the correct tooling and should converge in a prototype showing some (restricted) results. - Do not perform on-the-fly computation but store your annotations on a database to retrieve them when needed
There are plenty of reasons to support this recommendation, the most important are:
- Usability, on-the-fly computation is overloading the browser, making it slower and unresponsive.
- Processing a PDF will take more than 1 second, if this delay is propagated to the UX, the user will think the interface is slow.
- For small paragraphs it can be done, but it has to be handled asynchronously in the interface or the user will notice.
Future projects and prospects
Indexing a corpus of publications by extracting keywords via entity-fishing can significantly increase the discoverability of these publications. During the workshop, however, we found that such indexing only makes sense if it includes a very high number of publications. In view of this, we can imagine forms of a unified catalogue and a federated search engine for publications of different platforms indexed through entity-fishing. The realization of such a catalogue seems to be something that goes far beyond the possibilities of a single institution and requires the action of distributed research infrastructures that, as in the case of OPERAS, can coordinate the activities of several stakeholders. More precisely, OPERAS intends to use the entity-fishing service as one of the key components of its future discovery platform to be developed between 2019 and 2022.
Cite as
Bertino, Andrea, Foppiano, Luca, Arias, Javier, Ekanger, Aysa, & Thoden, Klaus. (2018, November 1). Entity-fishing for Scholarly Publishing: Challenges and Recommendations. Zenodo. http://doi.org/10.5281/zenodo.1476475
]]>

AEUP, in cooperation with the projects Métopes and HIRMEOS, organizes the workshop From Text to Structured Edition – Producing XML-TEI Content, from 11 to 13 December 2018 at Göttingen State and University Library.
Métopes, developed at Maison de la Recherche en Sciences Humaines in Caen as a project framework, aims to realize a set of tools and methods to allow the distribution of digital content in standardized environments with high interoperability potential. Métopes contributes to global rationalization of the publishing process by promoting the implementation of new multimedia distribution strategies and ensuring the sustainability of content and metadata. By supporting the production of standardised content (XML-TEI), the Métopes framework enables common catalogues or other content aggregation of associated publishers and content providers (metadata and content) in established industry standards such as ONIX.
The workshop will focus on a tool kit for scholarly publishing from the Métopes framework that facilitates transformation of different text formats in standardized content (XML-TEI). The workshop includes a series of talks, hands-on tutorials and practical exercitations. During the first day, participants will get general information about an XML-based workflow and the benefits for publishers adopting such a production workflow. On the second and third days, participants will work with the Métopes tool-kit and learn about its features and possibilities. The Métopes developers will guide the participants through the use of the tool and show them best practices to enrich their documents with XML-TEI.
AEUP members’ specific needs in terms of Latex, OJS for full text broadcasting and proofing, use of specific sets of standardized metadatas querying national and international database API will be considered.
The workshop is aimed at editors and publishers who want to acquire knowledge and experience with tools for creating standardized documents in XML. No previous knowledge is required, besides an open attitude towards new technologies and maybe yet unfamiliar standards.
Basis requirements:
Participants of day 2 and 3 need to bring a notebook/laptop with administration rights to install the Métopes software at the beginning of the workshop. We recommend one machine per user. In exceptional cases, one computer per publishing team may work as well.
Technical requirements
Windows or Mac OS (from 10.7.5);
– Microsoft Word and/or LibreOffice;
– XMLMind Personal Edition version 7.6
(Windows: xxe-perso-7_6_0-setup.exe; Mac: xxe-perso-7_6_0.dmg);
– Adobe Creative Suite, Acrobat Reader (optional, but recommended);
Files
Participants are recommended to bring sample files from their publishing program, from basic (text, notes, headings, quotes…) to complex texts (images, tables, bibliographic references, composite floating text, equations/formulas etc.)., to consider a progression during the training session.
Please note:
Number of participants for day 1 (half day): up to 80 persons.
Number of participants for days 2-3 (two full days): up to 25 persons.
AEUP members have the right of way. In case of a high number of registrations participation is limited to one person per institution. Please register here!
Contact us at [email protected]; HIRMEOS/local organisation: Andrea Bertino, [email protected]
]]>Entity-Fishing for Digital Humanities and Scholarly Publishing
Tuesday, 04 September 2018, 9:30-17:00
Niedersächsische Staats- und Universitätsbibliothek Göttingen
Vortragsraum, SUB historical Building
Papendieck 14
37073 Göttingen
https://goo.gl/maps/yWCuqdhtXNy
In the course of the project, different workshops are being organized in order to present and discuss the implementation of services and tools for digital monographs on Open Access publishing platforms. After the workshop at the University of Turin about the role of identifiers in research evaluation, now we want to discuss the possible application of entity recognition to digital publishing.
Entity-fishing is a service that enables the automatic extraction of concepts via Wikidata, so that persons, locations, organizations etc. can be uniquely identified and disambiguated. The HIRMEOS partners have tested various applications of this service on their digital platforms and for a quick overview you can have a look at our factsheet.
The workshop is organized into two main parts. During the morning session, the entity-fishing service and its meaning for scholarly work will be presented. In the afternoon, after a short presentation of the last experimental implementations on our platforms, we will focus on practical issues related to other possible use scenarios of the HIRMEOS entity-fishing service. To this end, we plan a roundtable in which three proposals for new usages of this service on digital platforms will be discussed in detail, paying particular attention to technical aspects. In this way, it should be possible to find concrete solutions for the specific difficulties in implementing a certain use scenario and, more generally, to define guidelines for future applications of this service by publishers who are not directly involved in the HIRMEOS project.
This is the workshop agenda:
HIRMEOS WORKSHOP
Entity-Fishing for Digital Humanities and Scholarly Publishing
Göttingen, Papendieck 14, SUB historical building, Vortragsraum, 4th September 2018
9:30–9:45 Introduction (Margo Bargheer, SUB)
9:45–10:00 The HIRMEOS Project (Andrea Bertino, SUB)
10:00–10:40 Entity-fishing: from text to concepts and beyond (Luca Foppiano and Laurent Romary, INRIA-DARIAH-EU)
10:40–11:00 Coffee break
11:00–11:45 Entity-fishing: Demo and Questions (Luca Foppiano and Laurent Romary, INRIA-DARIAH-EU)
11:50–12:30 Retrieving entities from publications in linguistics: Glottolog and Concepticon (Sebastian Nordhoff, LangSciPress)
12:30–13:40 Lunch
13:40–14:00 Entity-fishing service on the HIRMEOS platforms (Andrea Bertino, SUB)
14:00–14:15 Usage scenario I: Entity-fishing at ScholarLed (Javier Arias, Open Book Publishers)
14:15–14:30 Usage scenario II: Entity-fishing at Septentrio Academic Publishing (Aysa Ekanger, University Library of Tromsø)
14:30–14:45 Usage scenario III: Entity-fishing service for the Edition Open Access (Klaus Thoden, Max Planck Institute for the History of Science)
14:45–15:15 Coffee break
15:15–16:30 Roundtable on new usage scenarios. (Moderator: Stefanie Mühlhausen, SUB)
16:30–17:00 Conclusion. Overview and guidelines for service implementation (Margo Bargheer, SUB)
As space is limited, please register prior to the workshop: https://goo.gl/forms/3EAqo0w00r74bTL63
Please feel free to distribute this invitation to everyone who might be interested.
We are looking forward to seeing you soon,
The HIRMEOS consortium
]]>
The Digital Humanities at Oxford Summer School (DHOxSS), which offers training to anyone with an interest in the Digital Humanities, offers eight workshops which are completed by some plenary lectures:
- An Introduction to Digital Humanities
- An Introduction to the Text Encoding Initiative
- Quantitative Humanities
- Digital Musicology
- From Text to Tech
- Hands-On Humanities Data Curation
- Linked Data for Digital Humanities
- Crowdsourced Research in the Humanities
Considering that Wikidata is essential for the entity-fishing service used by the HIRMEOS project to enrich the texts of the open access monographs published on its digital platforms, the author decided to attend the workshop introducing concepts and technologies behind Linked Data and the Semantic Web and their meaning for DH.
The workshop, organized and conducted by Dr. Terhi Nurmikko-Fuller, lecturer in Digital Humanities at the Centre for Digital Humanities Research at the Australian National University, allowed also those participants who, like the author, had no or little knowledge in the field of computer science to become familiar with the main concepts underlying the transformation of a simple dataset into a structured data system. During the workshops all participants were encouraged to put into practice the notions acquired, mainly by sketching ontologies, structuring data in the turtle format and using the SPARQL query language.
Terhi and the two co-trainers John Pybus and Graham Klyne first introduced the notion of the Semantic Web. This is mainly an overall view of the web – I would call it a kind of ‘regulatory ideal’ of the ‘computation reason’ – which manifests concretely itself in the effort to create a Web of Data, i.e. an architecture of (possibly open) linked data. These data present should ideally follow these standards:
★ They Are available on the Web (whatever format) but with an open licence, to be Open Data
★★ They Are available as machine-readable structured data (e.g. excel, not an image scan of a table)
★★★ They Present a non-proprietary format (e.g. CSV instead of excel)
★★★★ They Use open standards from W3C (RDF and SPARQL) to identify things
★★★★★ They Are linked to other people’s data to provide context
According to this paradigm, the web should become a system of data entities which are recognizable by unique identifiers (http URIs), related to each other and created in such a way as to be readable by machines. The ultimate goal of the Semantic Web is therefore to have a hierarchical data architecture rather than a simple collection of documents. However, a total, omni-comprehensive architecture of the world (of data) remains an ideal far away from actual practice. More relevant for practice is the general aim of this vision, namely a reduction of complexity of the considered dataset which it is possible when this set is structured according to specific knowledge needs. In their rawness, data are not really useful for the digital humanist. Only if structured by an ontology, the dataset become fully suitable for scholarly investigations. An ontology is an “explicit specification of a conceptualization” (Gruber, T. R: A translation approach to portable ontology specifications. Knowledge acquisition, 5(2),1993, p. 199-220.)

Ontologies consist of categories and relationships which are applied to specific datasets in order to confer a semantic structure. This means that an ontology is the result of a conscious selection according to specific research needs. By abstracting a little bit, we can so think an ontology as a structured complex of decisions allowing the interpretation of a dataset – where interpretation means reading and querying data in order to obtain, in response, a subset of data linked to each other in an interesting way. Therefore ontologies are not something absolute, i.e. not independent of the activity of the subject who needs them to expand its knowledge. Ontologies cannot be considered a true or false reflection of an external reality (of data), but just a pragmatic constructions. More concretely, ontologies are semantic models articulated in a specific syntax and their materiality is that of a piece of software.
In the course of second day we learned that the development of an ontology usually involve the following phases:
Specification, in which reasons and aims of the ontology are assessed and determined.
Conceptualisation, dedicated to planning out structure, classes and properties of the onotology
Formalisation, in which the ideas are realised in a model, and the hierarchy of concepts is defined
Implementation, in which the language the editor software and, if necessary, the reasoner are selected.
Evaluation, in which the ontology is tested against SPARQL queries or through an online validator
Documentation, in which information regarding the design decisions and the rationale are outlined for the benefit of other users.
To understand how linked data architectures can be generated we need to become familiar with some basic concepts and definitions. First of all, we spoken about RDF (Resource Description Framework), the data model used to formulate the links between the different URI entities in order to make their relationships readable by machines. Afterwards we learnt how these relationships formulated through RDF can be expressed through different formats and that one of the most practical and functional to do this is turtle. In fact, this is not only readable by machines, but with a little exercise, even by our (in my case, totally inexperienced) human eyes. Through turtle we can represent the triples. i.e. the connections between entities according to a model subject-predicate-object and then implement them in software. It was shown, that an important reason for using turtle is its similarity with the query language SPARQL and we get to know a few of its syntactic elements.
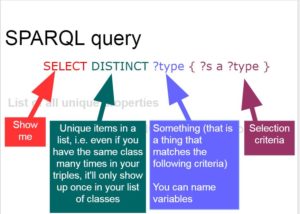
In several hands-on sessions we then attempted to sketch a simple ontology to be applied to a dataset provided by the instructors and afterwards to query them using SPARQL. The ontologies we had prepared were integrated into a dataset using some different programs: We exported our ontology from Protege as .owl or .ttl and we uploaded it in turtle (.ttl) format into Web Karma together with the data in a .csv format. Combining dataset and ontology we could create a knowledge graph and export it from web karma in RDF. It was suggested to use Blazegraph to generate the graph database.
To complete these exercises we were also introduced to various examples of ontologies used in the construction of linked data in a variety of disciplines like numismatic and musicology, and used for organizing metadata, exploring our cultural heritage, and visualizing data with innovative tools:
Sharing the wealth, Linking Discipline: Linked Open Data for numismaticsby Professor Andrew Meadows
Linked Data for Digital Musicology by Dr. Kevin Page
Defining the Cultural Heritage Knowledge Graph This session was run by Dominic Oldman and Dr Diana Tanase
Linked Open Geodata with Recogito This session was run by Valeria Vitale
OxLOD The final session of the workshop was a talk by Dr Athanasios Velios (University of Oxford) on OxLOD (Oxford Linked Open Data)
Linked Data and Digital Libraries In this session, Professor Stephen Downie provided an insight into projects that combine Linked Data methodologies and technologies with data from Digital Libraries.
In general, a particularly positive aspect of the workshop was the combination of three different didactic moments: theoretical explanations, practical exercises, and presentations of external projects. Perhaps, for the next edition, the time dedicated to the latter could be a little reduced to advantage of the first two session types. However such a workshop remain an unique opportunity to have, in just five days, a general understanding of the workflow related to the creation of linked open data and knowledge graphs and, in addition, ‘to learn how to learn more’, i.e. to know what people who are not IT specialists can do in order to progress autonomously in the usage of these tools.
The author was particularly interested in some aspects of the workshops related to Open Access and Open Science. It was very important to see more concretely why also linked data should be open, why only if open the linked data can deploy their full potential for the digital humanities. Indeed, the vision of the Semantic Web confirms that open science and digital humanities are not parallel paths, but two interconnected processes reinforcing each other.
Furthermore, considering the tasks of the HIRMEOS project, it was important to better understand how linked open data and the Semantic Web are going to play an important role in the enhancement of Open Access monographs. In fact, linked data could have an enormous utility for improving the discoverability of monographs: Converting library metadata into a system of linked data could be the way forward. What concrete practices such a transition will require it is an open and fascinating question!
Andrea Bertino
]]>PKP, founded 1998 by John Willinsky, is a multi-university initiative developing free open source software and conducting research to improve the quality and reach of scholarly publishing. EKT, an important National e-Infrastructure and a network for science, culture, research and innovation, has been a major adopter and advocate for PKP’s Open Journal Systems (OJS) and Open Monograph Press (OMP) both in Greece and throughout Europe. Within the framework of the HIRMEOS project, EKT has contributed in particular to the implementation of persistent identifiers on the Open Access publishing platforms of EKT- ePublishing, Göttingen University Press, Oapen, Openedition Books, and Ubiquity Press .
This new partnership opens up exciting perspectives for Open Access scholarly publishing and underlines the importance of research infrastructures capable of coordinating the activities of different kinds of stakeholders. To find out more about the challenges related to the development of such infrastructures, you can participate in the conference organized by EKT as member of the OPERAS-D consortium: Open Scholarly Communication in Europe. Addressing the Coordination Challenge. Here the program of the OPERAS conference which takes place from 31 May to 1 June 2018 in Athens.


The conference offered a rich and well-structured programme with participants from across Europe and from different kinds of communities, including scholars, university library officers, scholarly publishers and research administrators. The advisory board and the organising committee found a convincing balance between presentations with different concepts and ideals of Open Access and Open Science: Together with speakers intending the Open Science paradigm as a radical alternative to the current logic of scholarly research and publishing, there were also scientific publishers interested in presenting their tools and services for scholarly research.
Different Views on Open Access and Open Science
The conference was opened by Sir Timothy Gowers, Professor of Mathematics at the University of Cambridge, Fields Medal Winner and initiator of the boycott against Elsevier, who discussed the various incentives that give the current system its robustness and made some suggestions on how to weaken it (Perverse incentives: how the reward structures of academia impede scholarly communication and good science). Nevertheless, Federica Rosetta of Elsevier presented the publisher’s services to support the reproducibility of research results (The reproducibility challenge – what researchers need). It would have been interesting to bring such different views on Open Access and Open Science into direct confrontation within a round table. However, the audience participated lively in the discussions and gave the speakers the opportunity to further articulate their positions.
On Open Science in the Scandinavian world
Among the talks dealing with the dissemination of Open Science in the Scandinavian world, we were particularly impressed by Beate Ellend’s speech on the activities of the Swedish Research Council (Coordination of Open Access to Research publications in Sweden). Sweden seems to have a well-structured plan to outline an overview of the national open science. In its Proposal for National Guidelines on Open Access to Scientific Information (2015), the Swedish Research Council has identified a number of obstacles to the transition to an Open Access publication system. On this basis, the Swedish National Library initiates and coordinates five studies to be carried out in the period 2017-2019. One of these concerning Open Access to academic monographs is expected by the HIRMEOS consortium great interest. Like the Landscape Study on Open Access and Monographs (2017) presented by Niels Stern, such studies can confirm how important it is to base concrete policies for Open Science on a precise reconstruction of the needs and problems of individual scholars and research institutions.
On HIRMEOS and OPERAS
HIRMEOS discussed its tasks and activities with many participants at its poster. The project is already well known to the public, especially to officers of academic libraries and university presses. We observed an increasing interest in the growing research infrastructure OPERAS. Some projects presented at MUNIN has already contact points with the concept of a distributed research infrastructure; e.g. SCOSS: A Global Sustainability Coalition for Open Science Services presented by Vanessa Proudman. This new global coalition is currently in the middle of a pilot project. It intends to enable the international research community to take responsibility for developing and maintaining Open Science services through its institutions and funding organizations. It will create a new coordinated cost-sharing framework to ensure that non-commercial OS services supporting the development of broader global Open Access and Open Science will continue to be maintained in the future.
The participants of the conference we came into contact with were particularly interested in the annotation and name-based entities recognition services which HIRMEOS is implementing on the five digital platforms involved into the projects. Some relevant applications of the entity recognition techniques will already be presented at the beginning of the next year.
]]>
The conference provided a good mix of plenary sessions, workshops and poster sessions focusing on a variety of Open Science aspects such as open access models and platforms, innovative dissemination practices, open peer review, text and data mining, the European Open Science Cloud (EOSC) pilot, FAIR data. Key note speakers included renowned scholars like Prof. Nektarios Tavernarakis (from FORTH-Hellas and recipient of multiple ERC grants), Prof. Jeffrey Sachs (from the Earth Institute of Columbia University and an influential world leader) and Prof. John PA Ioannidis (from Stanford University and one of the most influential researchers worldwide) who all highlighted the importance of open science in attaining goals of global significance like the UN Sustainable Development Goals and tackling the reproducibility crisis in research.
The workshops gave participants the opportunity to acquire a more in-depth perspective of diverse aspects of open science such as policies, the importance of training and skills, the establishment of rewards for those practicing open science and the introduction of incentives, the availability of tools and services and the development of appropriate infrastructures. Open science experts gave insightful presentations and provided examples of resources available to stakeholders (OpenAIRE toolkits for researchers, PASTEUR4OA policy templates, FOSTER services) followed by stimulating discussions with workshop participants. The variety of topics and approaches chosen attracted researchers, librarians, IT experts as well as representatives from research funding and research performing organisations. Throughout the three-day event it was made evident that collaboration among stakeholders is a key element in achieving the transition to open science.
The Open Science Fair 2017 video is available on Vimeo: https://vimeo.com/233290266
Marina Angelaki, National Documentation Centre/NHRF (Athen)
]]>